

Grounded Information Extraction and Semantic Search using Large Language Models
Matt Maufe | 4th July 2023
For many of us, Large Language Models (LLMs) no longer need any introduction, having taken the tech world by storm with offerings like ChatGPT, but in short, an LLM is a tool that continuously generates the next word in a sequence based on what words are likely to follow the previous ones.
LLMs trained on enough data can often start to approximate actual knowledge about the world through this process: If prompted with “Describe the temperature of the Sahara desert: It is ___,” the next word will usually be “hot.” From this simple mechanism, complex behaviour and knowledge can emerge.
In particular, ChatGPT has often been referred to as a “Google Killer,” and one popular opinion flying around is that when you can just ask a hyperintelligent AI any question and receive a detailed answer, with the capability for further discussion, scrolling through ad-riddled Google search results doesn’t appeal.
However, as we discuss in another recent blog post, LLMs also have some inherent limitations: they don’t store any information in a retrievable form, are prone to hallucinations (inventing facts, citations, etc., out of thin air), and their output is difficult to control (a well-engineered prompt can guide them in a particular direction, but it’s very much not a hard rule).
With these in mind, it’s difficult to see how they might be turned into an adequate replacement for Google: Yes, you can ask them questions and potentially get some great answers back, but you might also get three paragraphs of utterly confident misinformation. ChatGPT’s tendency to invent quotes, citations, and even whole legal cases out of thin air has been well-documented.
This is because these models are not “grounded” in fact: There’s no external information source that they’re consulting; they’re essentially going off of hazy mixed-up “memories” of information they’ve seen before. And in fact, the mechanism through which they talk back is inherently one that’s very difficult, perhaps impossible, to ground: The only way to input this external information into the model at conversation time is by adding it to the prompt, and there’s no guarantee that it’ll listen to that close enough. You can lead an LLM to facts, but you can’t make it listen.
Happily, there’s a way to leverage the power of these models without sacrificing reliability and control: You can combine them with a “head,” a task-specific extension of the model that modifies its raw output. For instance, an Extractive Question Answering (EQA) head would take the model’s raw output and use the information encoded in it to answer questions with a short quote from the input text. In fact, this “finetuning” process can often improve performance on a given task.
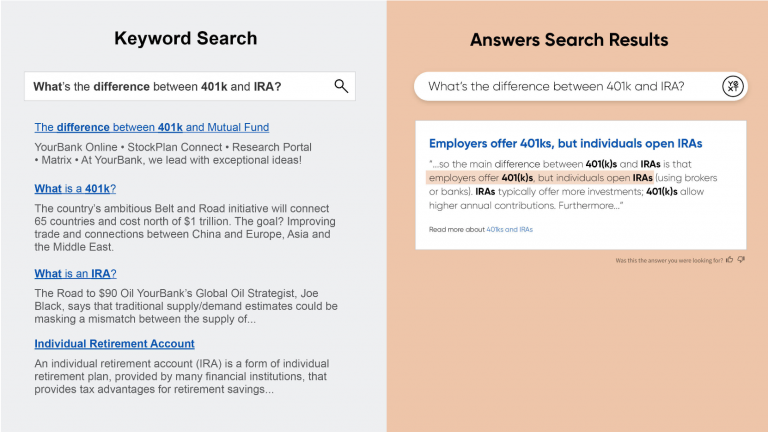
An example of an EQA system (right) with the answer highlighted in orange. Original image from Yext.
You can still take advantage of the knowledge that LLMs learn through their training, and by constraining the output to be a quote, you can avoid it simply by making things up. Of course, it can still be incorrect or mislead you with an out-of-context quote, but by providing context (as above), the end-user can sense-check the answer.
There are two main problems with this approach, however:
- You need to be able to modify the model — and API access or prompting isn’t enough.
- You need to provide it with the proper documents to extract answers from.
The first point is relatively straightforward: Modifying the model this way isn’t possible without access to its internal state, which APIs don’t provide. Fortunately, various open-source alternatives, such as Meta’s LLaMA, can provide similar accuracy and allow for tweaks like this.
The second point is more complex, and I’ll discuss it in detail:
Building a Knowledge Base
A grounded model can then query this knowledge base and produce answers based on it. Effectively, because models don’t have any real long-term memory of their own (only patterns they’ve seen and the short-term memory of their input prompt), the knowledge base substitutes for it and can help the model avoid outputting misinformation.
For instance, a grounded model asked to summarise World War 2 might select appropriate data from the knowledge base, incorporate it into the input prompt, and create a simple summary. An ungrounded LLM would have to rely on any information provided in the prompt (necessitating you to do some initial research) and hazy information from the texts previously seen during training — the risk of it making something up, or forgetting something, is a lot higher¹
So if knowledge bases can reduce hallucinations and make it easier for us to get information, why don’t we use them everywhere? Well, they often take a lot of time and effort to create.
In the above example, we would have to create a suitable store of high-quality documents that include data on WW2 and a mechanism for the model to identify the most relevant ones to use.
For some tasks, the former isn’t necessarily too difficult to do — many free datasets covering news, sports, science, and so on exist in text form and can be collated. But it’s often harder if you have a more specific domain that you want to focus on, like private equity.
Various solutions exist for selecting the correct information, depending on the use case and the type of knowledge base. For instance, semantic search over vector databases can work very well for EQA use cases: Each document in the knowledge base is stored as a vector. When the user asks a question, we encode it into a vector and find the most similar documents (and thus, those most likely to contain the answer). Various off-the-shelf solutions, such as Pinecone or Milvus, exist for setting this up.
However, information may be spread out over several documents — perhaps one document mentions that John Smith is 57 years old, and another discusses him becoming the CEO of Example Corp. Neither document can individually be used to answer a question like “How old is the CEO of Example Corp?”, and a solution like the above would often be restricted to looking in a single document for the answer.
Workarounds do exist, you can combine document texts or run it several times with sub-questions and concatenate the answers using a generative model, but these have issues of their own: Combining texts scales poorly (especially given that models have limited input sizes), and introducing generative models re-introduces the risk of hallucinations — the very thing we wished to avoid.
Knowledge Graphs
An excellent solution to this problem is to use these raw documents to create a knowledge graph. Essentially, this represents the documents’ information such that they can be traversed and queried in a more structured way.
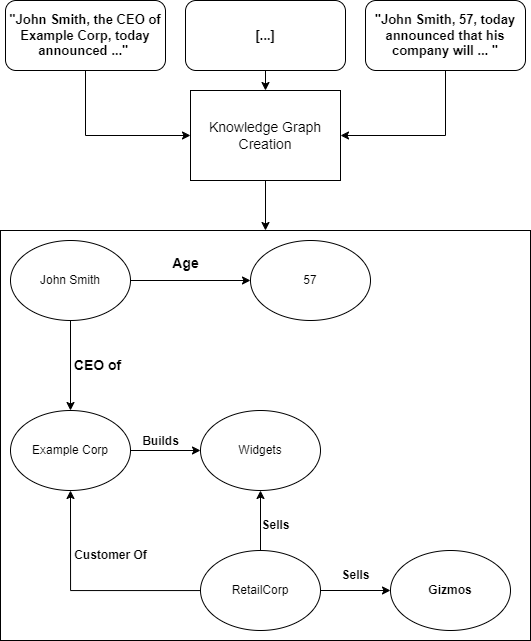
An example of a knowledge graph. Each entity has a relationship with other entities.
In the above, we have combined the information in the documents to create a single unified representation where each entity has a relation to other entities. The user’s question can then be translated into a formal query and applied to the knowledge base. Starting at the specified entity, “Example Corp,” we can traverse the “CEO of” relation and identify John Smith as its subject. We can then traverse his “age” relation to answer the question.
Tangentially, this kind of structure can also provide some significant wins for explainability: Whilst neural networks are challenging to interpret at the best of times, and LLMs can hallucinate their own explanations, here we can provide a very faithful explanation in two parts: The formal query that we derived from the question, and the path that was traversed in the knowledge graph, so that the user can see exactly why the model output the answer it did.
More importantly, we’ve been able to answer the user’s question accurately and with information from multiple sources without relying on generative approaches or multiple questions.
Knowledge bases can be expanded over time, e.g. by adding more documents to the database. So the model can keep up-to-date with current knowledge more easily without either being frozen in time by its training data or having to rely on searching the internet at runtime. In the above, we can see that once other documents referencing “RetailCorp” were added, new entities were created in the graph and even linked to old ones where appropriate.
By using a temporal knowledge graph, we can even attach timestamps to this information to better answer user queries: Perhaps John Smith wasn’t always the CEO of ExampleCorp and replaced Bill Smith. By adding temporal information here and creating appropriate constraints on the query, we can ensure the model looks at the correct set of information.
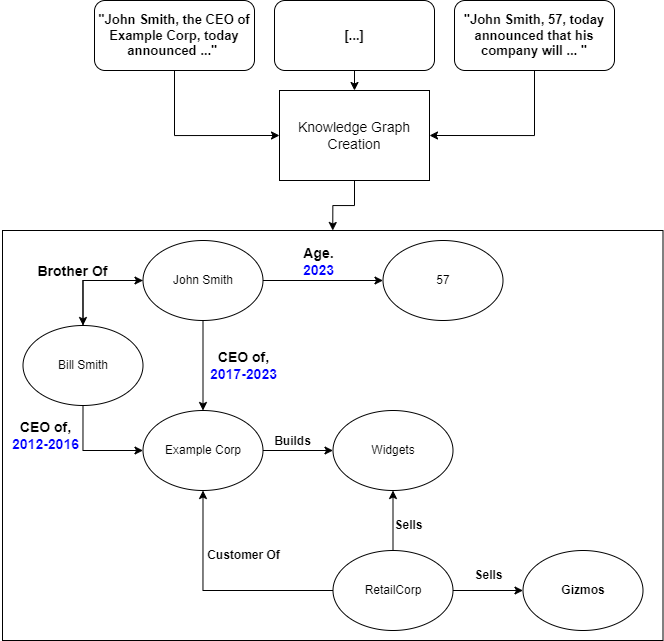
An example of the knowledge graph with temporal information in blue.
Reference
[1]: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Lewis, Perez, et al, 2020





