Turning a Private Equity origination strategy into proprietary Machine Learning models
Syfter Team | 30th October 2022
Summary
In the latest blog in our series of AI for Private Equity, Filament CEO Phil Westcott explains how Private Equity firms are using AI to enhance their investment strategies.
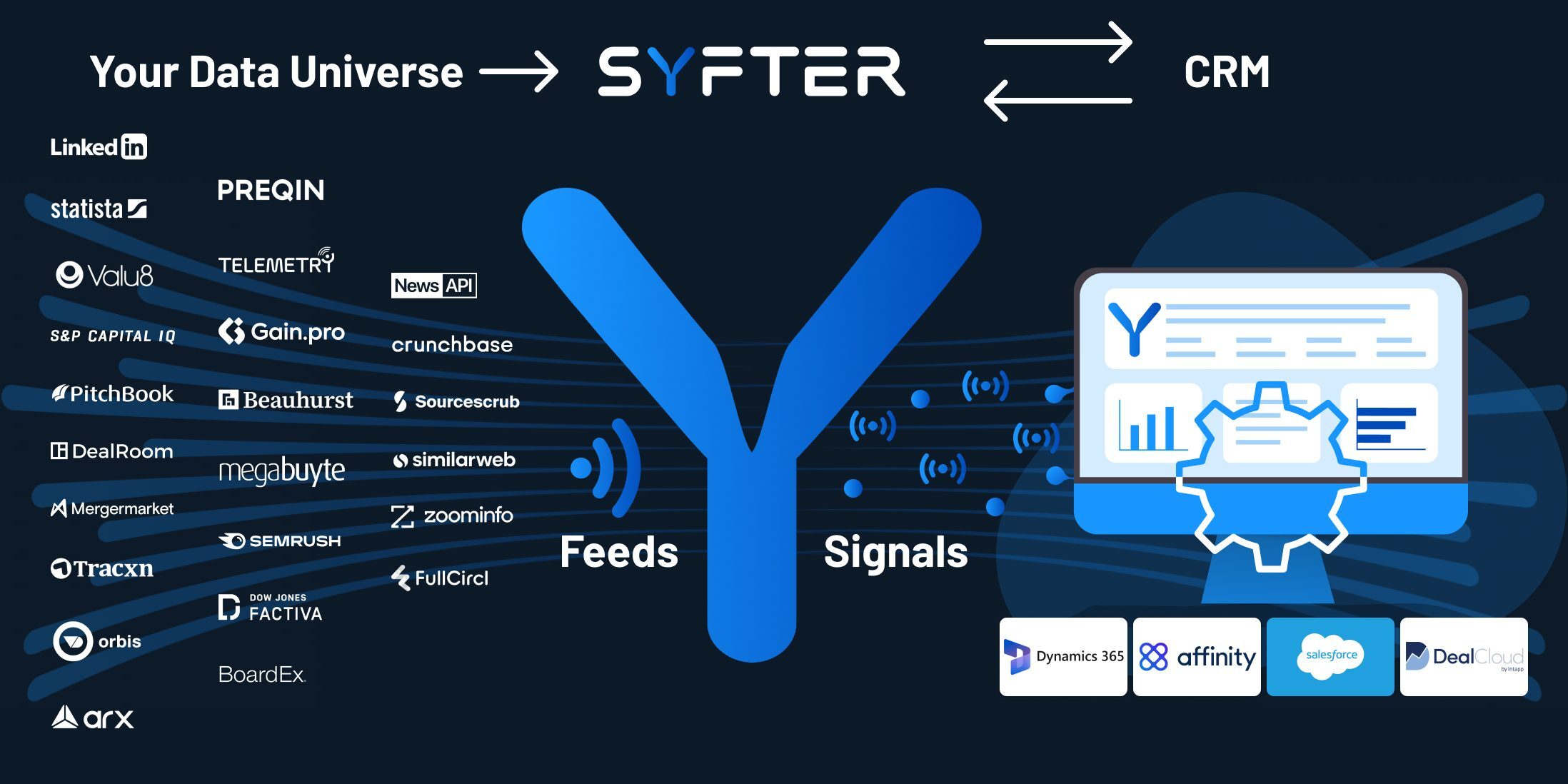
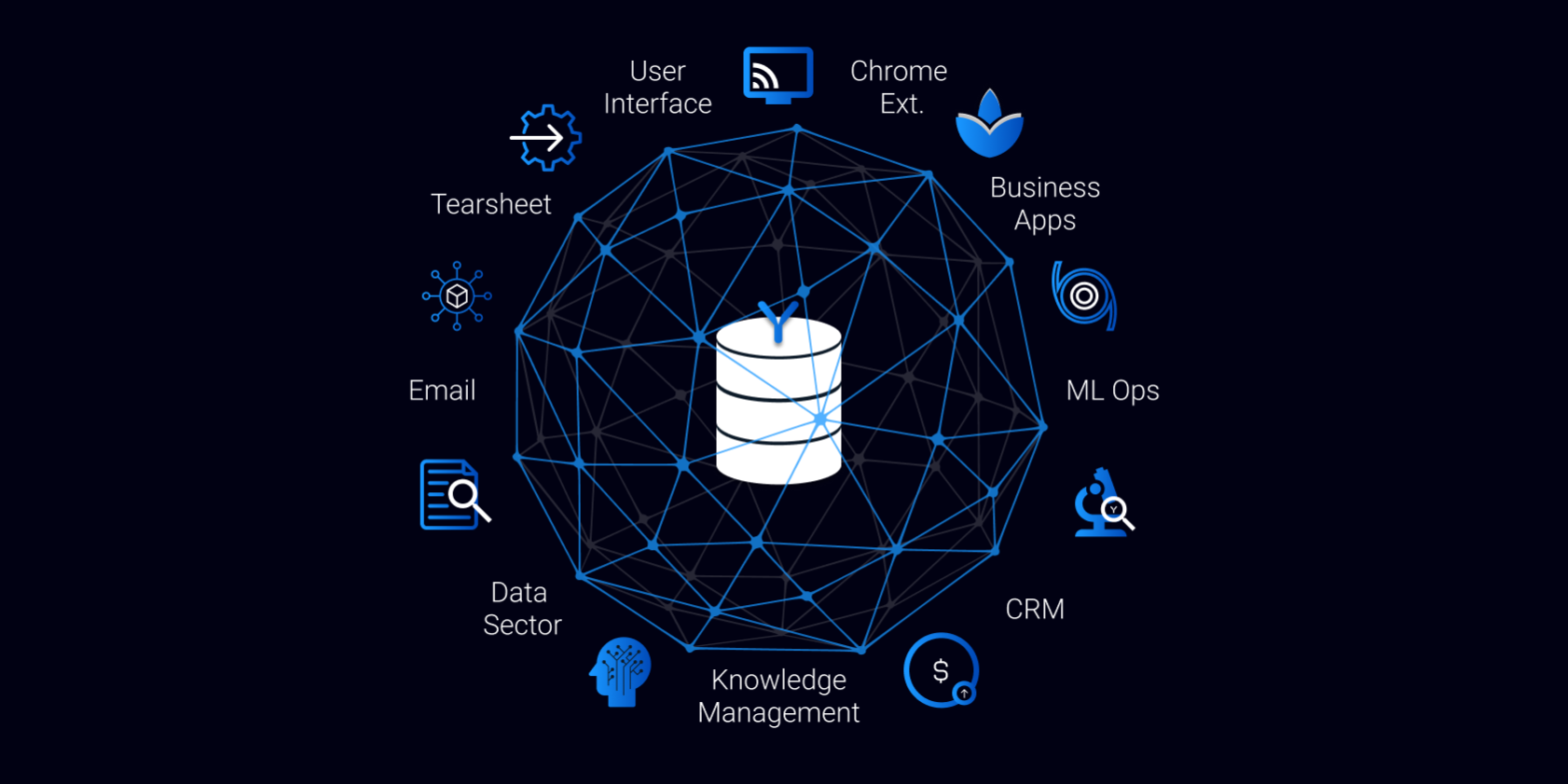
Over the past few years, Filament has been engaged by a host of Private Equity, M&A and other investment firms to boost the efficacy and productivity of their origination process through the use of AI. This gives them real-time competitive insight and a long-term strategic advantage. Essentially, this is a process whereby their investment experts cooperate with our Data Science experts to train proprietary Machine Learning models that capture their unique investment strategies. These models are then deployed into an operational platform. This industrialisation step involves solving the considerable data engineering challenges associated with running Machine Learning algorithms on live data. We have built our Syfter platform to fast-track that process, meaning we are able to stand up these proprietary platforms in weeks, not years.
- A caveat – this blog is pitched at the business user of an AI-powered origination platform. It explains the process of getting to a valuable solution but skims over the details of Machine Learning approaches. For more details on that, I’ve linked to excellent blogs from my Data Science colleagues at Filament.
In this blog, we explain the process for tuning your investment thesis into proprietary Machine Learning models. There are 7 key phases:
1. The collation of data: Most Private Equity firms leverage a host of data providers to gain a competitive insight into the market. In simple terms, these data sets can be grouped into the following categories: News, Financial, Deals, Executives & Marketing. Before we get involved, analysts have to flip between data provider dashboards and collate their insight into spreadsheets or their CRM. In this step of the process, we integrate all the useful datasets into one platform and match all the company data to one entity to give that 360-degree view of a company. The data source selection is iterative and based on the best tactics to elicit the right company KPIs that suit the investment strategy (see steps below). Often there is an opportunity to consolidate data providers or opportunities to add new data sources to plug the gaps, or enable new sourcing strategies.
2. Starting with a rules-based approach: The first step is to reduce the company universe into the relevant sector and size that meets the target investee profile. This requires a rules-based approach that allows you to select a sub-universe of companies by size (revenue or employee numbers), sectors of interest or geographies of interest. Through our user interface, each analyst is able to tune these rules and add secondary conditions, such as growth rate or critical conditions that have to be met for a company to be considered (e.g. ownership structure). You can also use generic machine learning models to find similar companies to those in your existing portfolio.
3. Designing the proprietary Machine Learning models – This step is about turning your analyst strategies into the investment firm’s own proprietary models. This is the secret sauce and why proprietary AI sourcing solutions will also be essential to ensure a firm is building a competitive advantage. First, the analysts must identify the weak signals that they, as experts, pick up from the market. This might be an indication that a company is ripe for investment, is looking to expand into new markets or geographies, or is reinforcing its team (R&D or NEDs). Your analysts will know where to find these clues and the lines of reasoning they go through to (i) raise the probability of the target company meeting their criteria, and (ii) select the optimum timing to approach the CEO. There is no standard answer to how to do this because every investment strategy and sourcing tactic is different. However, the process is always the same: it is an iterative collaboration between the investment analyst, the Filament business analyst and the Filament data scientist. The first two individuals yield the hypothesis and the data scientist then explores the best ML techniques to turn that hypothesis into a Machine Learning model.
4. Analyst annotation – This is the process for bottling your subject matter expertise into machine learning models through the process of data annotation. This creates the proprietary model, wholly-owned by the investment firm. For the analyst, the annotation is somewhat dull, but the incentive is being the designer of the house AI. The analyst will typically be required to annotate a fair number of documents, news items or paragraphs about a company, to identify specific signals which will ultimately influence the scoring of that company’s attractiveness. This builds the ground truth data set for the weak signals. Once a working baseline of useful weak signals has been found and modelled (having iterated on step 5 below), annotation can be simplified to providing a single yes/no label for suitability at the company level.
5. Data Study – With the help of a Filament business analyst, the hypothesis and ground truth data is then passed to one of our Machine Learning scientists. We call this phase the “data study”. The process involves an investigation of different data science techniques to test and tune the hypotheses on the data. This involves the selection of hyperparameters and the tuning of parameters, a process very well summarised in my colleague Cynthia’s blog. We have helped some clients build over 100 ML models with 25 in operation at any time. Now with a set of weak signals and rules-based criteria, we run a further study on the company scoring, using these weak signals and rules-based criteria as the parameters to optimise. The analyst annotation of ‘good’ and ‘bad’ companies is used as the ground truth, although we will typically also look at existing portfolio companies as an unbiased view of what good looks like. The output of this phase is multiple child models – that capture different sets of weak models – and one overarching scoring model operating at a company level. Metadata captured about each company is also combined with the output from the child models. This first cut scoring model can then be deployed into the operational system.
6. Deployment phase – I often quote a colleague who states that “75% of the challenge of AI is software engineering” – this is very true in this context. The data integration identified in step 1, plus the models yielded from steps 2-5, now need to be integrated into a live system. The software engineering challenge – aka the ”plumbing” – when built bespoke, involves the skills of a full-stack software engineering team (front-end dev, backend dev, data engineering, quality assurance and DevOps). When built from scratch this phase can take the best part of a year. But many of the software engineering challenges are common to all investment platforms, irrespective of the secret sauce of their investment strategy. That’s why we built Syfter (Syfter.ai). We’ve essentially baked all this plumbing into a platform so that the deployment time reduces to a matter of weeks, letting our clients focus their investment on the proprietary secret sauce above. Sales pitch over.
7. Tuning the system through use: Another truism from a colleague is that “the ML performs worst on its first day of operation”. This is inevitable. When a combination of models – as described above – is first deployed into Syfter, it is raw and unrefined. However, even after the first few days of operation, feedback mechanisms improve the underlying models. Furthermore, analysts can develop their own custom views, based on their interactions with the system and their own sourcing tactics. From a project perspective, it is best to unveil the system to a Beta group of analysts, who can perform this initial refining, and can highlight any improvements. Then it can be unveiled to the wider team with full fanfare. On this point, it is relevant to add that these systems are not just used by the origination teams. Investment managers and portfolio managers can also glean significant advantage by tracking the weak signals emitted from their companies of interest.
Ongoing strategic view: Some of our clients have been running these origination systems for many years now. They have built up an incredibly powerful, enriched database on their target markets and company universe. This has achieved the primary objective, to make their deal sourcing even more effective, giving them ideas and early contacts that have led to deals. And secondly, it has allowed a far richer understanding of their investment landscape, informing strategic decisions of future investment strategies and providing a world-class CRM database for the years ahead.
Summary
In the burgeoning market of AI, one of the main issues is the business world’s understanding of the potential – and quirks – of AI technology. It can provide a huge strategic advantage, but it is deployed a little differently to conventional linear computing and has a slightly different value chain. With more and more Private Equity and investment firms investigating AI-based strategies, an understanding of the processes can only help. Hopefully, this blog has shed some insight into the process. If you are keen to learn more, feel free to contact me.